この記事は?
AHC で相対スコアが採用されているときのメタ戦略について書きます。主に次の 3 つについて考察します *1 *2 。
- パラメータ群の重要度把握
パラメータ群ごとの解法の改善が全体の相対スコアに与える影響を定量的に把握することで、どのパラメータ群を改善するのが効率が良いかが分かります - テストケースごとの行動最適化
ランダム性がある場合などに、テストケースごとにどのような戦略を取るのが最適かを検討します - 解法の優劣比較
手元実行時に解法の優劣比較やパラメータチューニングを行うための重み付け・評価方法
(目次はこんな感じ)
相対スコアとは
目的
コンテストによっては、テストケースごとの難易度(パラメータ)が異なることによって、普通に取り組んだときに得られるスコアに大きな(例えば 倍などの)差が生まれることがあります。この場合にスコアをそのまま合計すると、スコアが小さいケースをどんなに良くしてもほとんど意味がないということになってしまいます。これを避けるため、他のコンテスタントの結果に応じて相対的にスコアが決まる方式が採用されています。
定義
これまでよく採用されている相対スコアは、ケースごとにトップの参加者の絶対スコアとの比率でスコアが決まる方式です。
絶対スコアを最大化する問題か最小化する問題かによって、大きく 種類あります。
- 絶対スコアが大きい方が良い場合( AHC029 など)
- 絶対スコアが小さい方が良い場合( AHC031 など)
これらのふたつは、絶対スコアを逆数で定義すれば互いに入れ替わるという意味で、相対スコアの方式の差としてはあまり本質ではありません。本稿では特に明記しない場合は前者(絶対スコアが大きい方が良い場合)を想定します。
また簡単のため 関数は省略しています。定数
も本質ではないので、本記事内でも比率のみに注目する場合などは
を無視して議論します。
効果
相対スコア方式によりケースごとのスコアの最大値が常に一定になるように調整されています。ただしここで一定なのは「最大値」だけであり、トップ以外の参加者にとっては依然として重要度に差があることがあります *3 。
代替案として、スコア関数を工夫すれば重要度をそろえることができる可能性はありますが、次の理由などで難しいこともあります。
- 運営が参加者のスコアを事前に正確に予測するのは困難
- (スコアを予測できたとしても)どのパラメータでも重要度が一定になるようないい感じの方式を見つけるのは困難
- パラメータの範囲ごとにスコア計算方法を変える方法もあるが、運営側も参加者側も煩雑になる
- 得点方法の設定が本質のネタバレにつながる可能性がある
パラメータ群の重要度把握
目的
長期コンテストではさまざまなパラメータのパターンがあり、パラメータによって全く別の戦略が強いという場合が多くあります。しかしパラメータによって最終的な相対スコアに与える影響が大きく異なることもあるため、やみくもに取り組むと無駄な(最終スコアにほとんど影響を与えない)部分で改善に時間を使ってしまう結果になりかねません。
本章ではどのパラメータ(群)を改善すると最終スコアにどれぐらいの改善が見込めるかを定式化し定量的に計算することで、コンテスト中にどのように考えて取り組むのが効率的になるかを説明します。
記号の定義
本章全体を通して使う記号です。ふわっと書いているところもありますが、詳細は後述します。
| パラメータ(複数パラメータの場合も |
|
| パラメータが取り得る集合 | |
| パラメータが |
|
| パラメータが |
|
| パラメータが |
|
| 全テストケースにおける相対スコアの平均値 *5 | |
| 進捗 | |
| テストケースごとの得点の取りやすさ | |
| 進捗 |
前提
状況をなるべく簡潔にかつ本質を表せるようにするため、次のような前提をおきます。
- テストケースごとに、得点の取りやすさを表す指標
が定まっていて、
- テストケースごとのスコアは、ある
という変数によって
と表される。この
- トップの進捗は、自分の進捗の
倍(
)であるとする。
- 進捗を 1 増やすための労力はコンテスタントごとに常に一定
- 現状の自身の進捗は
- (特に明記しない限り)自身はトップではない
絶対スコアの定義はさまざまで簡単に上がる場面やそうでない場面があり統一的に扱いづらいので、労力を与えるごとに同じだけ伸ばせる指標「進捗」を媒介することで、効率を定式化しようとしています *6 。
寄与計算
相対スコアの影響を考察するには、自分とトップの絶対スコアがどのような関係になっているかを理解することが重要です。ここで想定すべき「トップ」は、下記の点で順位表の 1 位よりも強い仮想的な参加者であることに注意してください。
- ケースごとに最大値を取る
- コンテスト終了時点での結果を取る
自分の相対スコア(のケースごとの平均値)は次のように表せます。
労力あたり改善量
コンテスト中では、有限の時間でなるべく相対スコアを改善したいので、労力 *7 当たりの相対スコア改善量を最大化したいです。あるパラメータ のケースの改善を行うとして、労力あたりの最終スコアへの影響は
と表されます *8 。パラメータの発生率 を無視した
を「効率係数」と呼びます。
スコアのタイプ
スコアの得られやすさが線形になっている問題や指数的になっている問題があります。
線形タイプ
スコアが進捗に対して線形になっているものです。具体的には のような場合です。
この場合、トップのスコアは となります。相対スコアは、係数
を省略すると
となります。つまりテストケースによらず同じ相対スコアが得られることになります。
また改善を行った場合の効率を表す「効率係数」も、 であり、テストケースによらないことが分かります。
指数タイプ
スコアが進捗に対して指数関数になっているものです。具体的には のような場合です。
AHC029 では増資を行うごとに生産性が約 2 倍になるゲームだったので、スコアはおおよそ指数関数的に決まっていると言えます。ただし本問では増資回数が 20 回までと決まっていたので、 20 回の上限に達するような場合は指数関数ではなくなります。
この場合、トップのスコアは となります。相対スコアは
となり、
が大きいとき(易しいケースのとき)相対スコアは指数関数的に小さくなることが分かります。
効率係数は であり、こちらも
が大きいときは小さくなることが分かります *9 。
指数(逆数)タイプ
のような場合です。
AHC016 では予想が外れた回数が多いと指数関数的にスコアが減っていくスコア形式だったので、このタイプに近いと言えます。
この場合、トップのスコアは 、相対スコアは
なので、先ほどとは逆に
が小さいとき(難しいケースのとき)極端に小さくなることが分かります。効率係数
も
が小さいと小さくなります。なおここでは「難しいケースでスコアが取りにくい」を表現するため、指数部分を進捗の逆数としていますが、問題によっては別の関数を考えることが適切である可能性もあります。
ここまでのまとめ
ここまでの議論をまとめるとこんな感じになります。
| タイプ | 自身のスコア | トップのスコア | 相対スコア | 効率係数 | |
| 一般 | |||||
| 線形 | |||||
| 指数 | |||||
| 指数(逆数) |
極端な例
ところで、効率の話をしているけどこれがどれぐらい影響があるか *10 を例を挙げて説明します。
指数関数的なスコア
指数タイプで 、
の場合を想定します。これは近似的に AHC029 で、増資をするまでの時間がトップと 2 倍の差がある場合に相当します。ただしここでは簡単のため増資回数制限を無視して、さらに増資のタイミングによらずスコアは厳密に指数関数的に増加すると仮定しています。
| 自身の進捗 | トップの進捗 | 自身の絶対スコア | トップの絶対スコア | 相対スコア | 効率係数 | |
この例では、 が大きいケース(スコアが取りやすいケース)ではいくら頑張っても全体の相対スコアの改善は見込めません。逆に難しいケースでは改善した場合の相対スコアに与える影響が大きいことが分かります *11 。
(イメージ)
の範囲や
の水準によって形が変わるのであくまで参考ですが、線形タイプと指数タイプの効率を比較するとこういうイメージになります *12 *13 。指数タイプでは、スコアが取りやすいケースでは効率がめちゃくちゃ悪くなり得ることが分かります。

段階的なスコア付け
ある段階からペナルティが急激に大きくなる場合、その境目付近では(ペナルティが大きい側にいる場合)ほとんどスコアが得られないことがあります。
Rated ではないですが トヨタ実課題コンテスト では、①順番前後ペナルティなし、②順番前後ペナルティあり、③収容失敗ペナルティあり、という 3 段階のペナルティがありました。特に収容失敗ペナルティはそれがない場合と比べて桁違いのペナルティが出てしまいます。実際、私の例では収まった場合のペナルティは 3 万点弱、収まっていない場合のペナルティは約 300 億と、約 100 万倍のペナルティになっています。
この場合、トップ層にひとりでも収容成功した人がいると、収容失敗した参加者の相対スコアはほぼ 0 点になり、その範囲ではいくら頑張っても相対スコアにはほとんど影響がありません。
さらに時間伸ばしてなんとか収まった ----- Container Loadingのseed=3でペナルティ27200を達成!!!https://t.co/8dro9279q1
— きり (@kiri8128) March 9, 2023
解法の切り替わり
AHC030 では、 が小さいときはベイズ推定などを用いて、コストが 1 より小さいような、ほぼ理論値を出すことができました。
一方で がある程度大きくなると計算時間的に厳しくなってくるので 1 マスずつ掘るなど別の解法に変換せざるを得ない参加者も多かったと思います。このように計算時間などの理由でスコアを犠牲にした解法に移行する場合、その境目ではコストが不連続に大きくなります。仮に境目でコストが 10 倍程度に跳ね上がるとすると、最上位勢にひとりでも効率の良い方法で成功している人がいると自分のスコアは
以下になってしまいます。低い得点が得られる側の解法を使っている範囲では、改善する効率も悪くなります。あるいは言い換えると、成功確率が
程度でも、効率の良い解法にチャレンジする方が相対スコアの期待値は高くなります。
ノーペナ達成
AHC031 ではケースによってはコスト 0 (絶対スコア 1)が達成できることがあります。この場合、正のコスト(通常は 100 以上)を発生する解法では相対スコアはほぼゼロになります。
相対スコアでの影響度は、上位陣の何割ぐらい取れてるかが指標になる。
— きり (@kiri8128) April 1, 2024
「難しいケースで頑張って AC する」はスコア的にはほぼ意味なくて WA 消す価値は小さい。
むしろ今回だとコスト 1 ができそうな場合はむりにでも探すぐらいが良い(妥協 AC するぐらいなら確率低くても探し続ける方が良い)。 https://t.co/nvFHK6siUA
このような状況では、ノーペナ状態にならない範囲では頑張ってもスコアはほとんど伸びず効率が悪くなります。またこのような場合には多少確率が低くてもノーペナを狙う方が期待値が高くなります。
テストケースごとの行動最適化
さてここまでは「どのケースを伸ばせば効率が良いか」について考察してきましたが、少し話は変わってあるケース(パラメータ)に限定して考える場合の最適戦略について考察します。
ケースごとにはスコアが高いほど良いので、最適戦略と言ってもピンとこない人もいるかもしれませんが、場合によっては非自明になることもあります。
絶対スコアの場合
簡単のため、まずは絶対スコアの場合を考えます。
スコアが確定的な場合
スコアが確定的であればなるべく良いスコアを得るのが良いです *15 。
スコアが確率的に決まる場合
インタラクティブな問題や解法にランダム性がある場合はどうでしょうか?
テストケース数が十分にたくさんあると想定すると、テストケースごとに、得られるスコアの期待値を最大化するのが最善です(中心極限定理) *16 。以下でもこの前提で考えます。
相対スコアの場合
例題(問題設定)
ここで唐突に問題形式にしてみます。 AHC030 での戦略を想定していますが、特に問題を覚えていなくても(見たことがなくても)そのまま読み進めて大丈夫です。
下記の問題設定を考えます。
- インタラクティブな問題で、「ペナルティ」をなるべく小さくしたい
- 絶対スコアはケースごとの「ペナルティ」そのまま
- ケースごとの相対スコアは、
で定義される
次の 2 つの戦略候補があります。
① チャレンジ戦略
- 成功すれば低いペナルティを狙えるが、失敗すればペナルティが大きくなる。
- 具体的には、成功すればペナルティ
を達成できるが、失敗すればペナルティが
になる。
② 安定戦略
- 確実にペナルティ
を達成できる。
問題
チャレンジ戦略の方が有利になるのは、成功確率がどれぐらいのときか。
解答
【ネタバレ防止】(↓↓↓ クリックで開きます ↓↓↓)
全参加者のペナルティの最小値を とします。簡単のため
とします。
【考え方 1】
成功確率を とするとチャレンジ戦略ではペナルティの期待値が
、安定戦略ではペナルティは
となります。チャレンジ戦略の方がペナルティの期待値が小さくなるのは
のときなので、チャレンジ戦略の方が有利になるのはこの範囲のとき・・・
この考え方は実は誤りです。
相対スコアはペナルティの逆数に比例することに注意しましょう。
【考え方 2】
相対スコアの期待値は、チャレンジ戦略の場合の相対スコアの期待値は 、安定戦略の場合の相対スコアは
。前者の方が大きくなる条件は
です。
こちらの考え方が正しいです。つまり 70% 弱でもチャレンジした方が有利になることが分かりました *17 *18 。ペナルティがある程度大きくなると逆数関数もほぼ線形とみなして良くなるためこの影響は小さくなります。
自分がトップの場合の影響(上位勢向け)
あるケースで自分がすべての参加者の中でトップである場合、それ以上改善しても相対スコアは伸びません。しかし他の参加者の相対スコアを下げることができるので絶対スコアを改善する効果はあります。この場合の効果はどのように評価するのが良いでしょうか。
AHC では参加者を固定するとパフォーマンスは順位のみで決まるので、自分の順位に近い参加者(「ライバル」と呼びます)との相対的な位置を良くすることが重要です。つまり、自分の順位に近い参加者の相対スコアを一律 点ずつ下げることは、自分の相対スコアを
点だけ上げることと等価であると考えられます。
自分以外の参加者の中の絶対スコアの最大値を 点、ライバルの絶対スコアを
点とします。するとこの意味での効果は次の関数で表されます。
この関数の微分は
のようになり、 の境で効率が
倍に(一般には不連続に)悪くなり、それ以降も徐々に割合が下がります。
ここでも先ほどの指数型の労力あたり絶対スコア改善量を仮定すると、効率 は
となります。例えば 、
のときの効率をグラフにするとこのようになります。
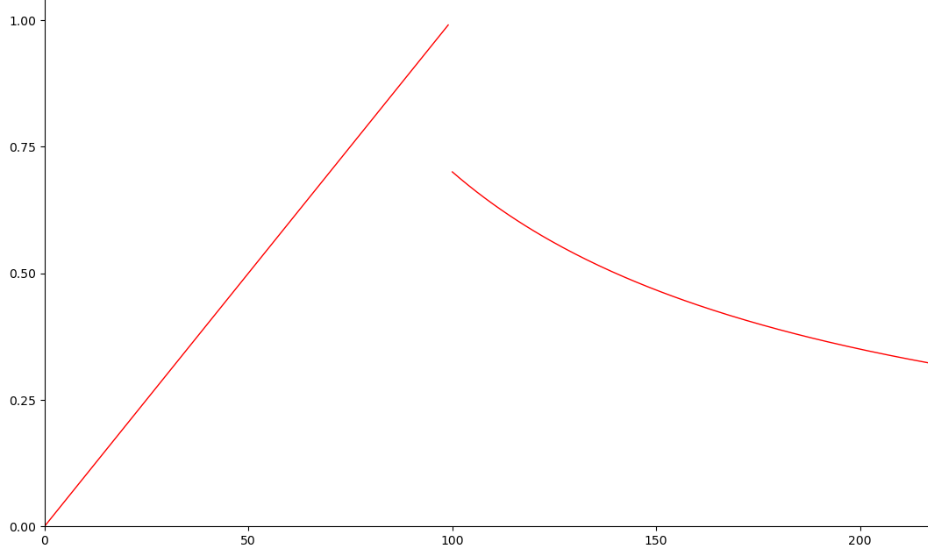
自分以外の最大スコアの直前ぐらいを推移する際に効率が最大になり、それを超えると不連続に下がる感じですね。
多くの人は恒常的にほかの参加者の最大値を大きく超えることはあまりないので基本的には絶対スコアの期待値(最小化する問題の場合は絶対スコアの逆数の期待値)が最大になるように行動すればよいことが分かります。
逆に自分が最上位の場合など「低確率でも良いスコアが出せれば他の全員のスコアを下げられる」ような可能性があっても、期待値以上にギャンブルをするのは良くないことが分かります。
なおこの例では としています。順位表上位勢の場合
が
に近付くので連続に近くなると思ってしまうかもしれませんが、運要素もあるので、順位表トップ付近であっても
にはならないのが一般的です。
例えば次の例を考えてみるとよいかもしれません。
運ゲー度
探索問題やインタラクティブ問題などで運ゲー要素が入ると上位勢であったとしても必ずしも高いスコアが取れる訳ではありません。
例えばインタラクティブがあり、理論上最適に行動した場合には の確率で 100 点が得られ
の確率で 10 点が得られるとします。多数の参加者がいるコンテストでは、少なくとも 1 人は 100 点を得ていると考えるのが自然です。この場合、相対スコアはの期待値は
です。運ゲー要素がないケースでは最適に行動すると相対スコア
が得られるはずなので、運ゲー要素が高いケースは(たとえ自分が上位勢であったとしても)得点効率が悪いことが分かります。
インタラクティブでなくても探索ゲーの場合は、たまたま良い解が見つかるかどうかでスコアがぶれるので、最上位勢でも相対スコア期待値が にならないことがあります。
解法の優劣比較
話は変わって手元実行時に解法やパラメータの優劣を比較する方法について。
少数のテストケースに絞って考察する方法
影響度が大きいパラメータ群のみに絞って試す方法
パラメータごとの影響度の違いについてはすでに考察しました。影響度が大きい部分に絞って(影響度が十分小さいところは無視して)比較すればよいです。
この方法は、影響度がケースによって大きく異なる場合に有効です。
代表テストケースを選出する方法
パラメータによって解法を変えている場合、解法のパターンごとなどに代表的なケースを固定して試す方法です。
コンテストの序盤などで知見を得たい場合などは、何がボトルネックになっているかなどの考察にこの方法が有効です。
多数のテストケースを回して比較する方法
多数のケース(100~10000 など)を回して重み付き平均を取る場合の方法です *19 。
単純平均を使う方法
相対スコアのコンテストでは相乗平均の下位互換になることが多いので、あまりおすすめしません。
提出時のスコア
提出時に表示されるスコア(絶対スコアの合計)も本質的には単純平均と同じで、問題によりますが基本的にはおすすめしません。例えば AHC029 ではケースごとのスコアに差が付きやすく、実際 1~2 ケースで絶対スコアの大部分を稼いでいるという人も多かったと思います。しかし実際にはこのようなケースは上で考察したように相対スコアにはほとんど影響しないケースです。しかもこの問題はインタラクティブの中でも点数がぶれやすい問題だったので、絶対スコアで良し悪しを判定するのはやや無理があり、たとえるなら「安い車を探したいときに金額の下 3 桁が小さいものを選ぶ」に近いかもしれません *20 。
提出時の絶対スコアの活用方法としては、ランダム性のない解法ではハッシュ値として使えるので、リファクタをした際などにスコアが変化しないことの確認に使うことができます。
相乗平均(対数平均)を使う方法
相乗平均を使う方法です。各テストケースのスコアを とすると、相乗平均は
と表せます。実装上は累積積を計算していくとオーバーフローするので、スコアの対数(
)を合計していって最後にケース数で割って exp *21 して戻せばよいです。なお対数平均を取るだけでも同様の指標になりますが、底に依存することもあり分かりづらいので指数関数で元のスケールに戻す方が直感的に分かりやすくなります。
なお、絶対スコアを逆数で定義しても相対平均による優劣は変わらないという性質があります。具体的には、ペナルティの逆数を絶対スコアにしている場合などには、どちらを使っても大丈夫です。
実装が非常に軽い割に単純平均に比べると使える場面が多いのでおすすめです。実際、トップと自分の絶対スコアの比率がほぼ一定であればこの方式で近似できることが分かります。ただし前述の指数型の場合のようにトップと自分のスコア比率がケースによって大きく異なる場合は使えません。例えば指数型( )の例では、 0 のときと 10 のとき(AHC030であり得る範囲)では約
倍程度、 0 のときと 100 のときでは約
倍程度おかしくなります。
トップの絶対スコア予測
トップの絶対スコアが予測できれば、理論上は自分の相対スコアの合計が計算できます。なお上でもあったように、ここで考慮すべき「トップ」は、コンテスト終了時点でのケースごとのトップであることに注意してください。
① 前回の自分のスコアを使用
おすすめしません(少し実装が増えるが②の方がまだまし)。
② 自分のスコアの最善値を使用する方法
場合によっては使えることがあります。
ただし、前述の指数的なケースなどは(自分自身がかなり上位でなければ)ミスリーディングになります。
③ 理論値による予測
AHC の最上位はとてもすごい *22 ので、基本的にはとてもすごいと思っておけばよいです。具体的には、何かしらの理論値が概算できたらそれに近いなど。
自分の相対スコアを予測するとき、「上位陣はどうせ理論値に近いスコアを出してくるんだろうなー」と思って予測するとだいたい良いかもです
— きり (@kiri8128) February 20, 2024
たとえば AHC030 では、コスト 1 あたりで情報量が最大で 10 程度 *23 などと考えると、状態数の総数からスコア理論値の上界が概算できます。
ケースごとの影響度の差が大きい場合はおすすめです。
④ 時間を伸ばして計測
「到達度」を上げるために、実行時間を伸ばして計測するのは上位陣のスコアに近付くために有効です。
一応、ほぼ「自身の最善値をトップだと仮定」だけど、「毎日実行時間10倍程度(全実行が6時間程度で終わる時間)で寝る前に動かす」って要素がそこそこ大事なので入れておきます。
— chokudai(高橋 直大)@AtCoder社長 (@chokudai) April 15, 2024
(伸びるポイントがだいたいそれでわかるので)
この方法の利点は、自分の方針が適切である場合、スコアの形状 *24 によらずトップに近い結果を得やすい点があります。特に高速化ゲーになる場合はかなり有効です。
ただし方針自体がいまいちである場合や、順位は良くても実行時間と関係ないところで劣っている場合などはそのままでは使えないかもしれません。また、自身もある程度上位に入っていることが望ましいため、初級者はそのままでは使えないかもしれません。
⑤ チートプレイ
③④と近いですが、「上位勢はクリアしているであろう障害」を外してみるなど、上位勢のスコアに近くなるように調整する方法も有効になる場合があります。
例えば次のような方法が考えられます。
- 推定パートをチートしてみる
- ある部分で理論値が得られることを前提とする
なんでもチートしまくれば良い訳ではなく、上位勢が達成しているであろうレベルに近付けるのが重要です。
極端な例
単純平均でなく相乗平均を使っていればおっけーみたいな風潮もあります *25 が、実際には相乗平均でもうまくいかない場面が多々あります。
「パラメータ群の重要度把握」の 「極端な例」 で挙げた例は、こっちでもうまくいかない例に当てはまります。やや重複もありますが、こちらの意味でも再考します。
なお相乗平均はどのスコア帯であっても 倍になるという影響を等しく評価する方法であることに注意してください。
指数関数的なスコア
相対スコアが のときに
倍になるのと、相対スコアが
のときに
倍になるのでは 1 億倍差があります。
段階的なスコア付け
実課題コンの例では、ペナルティが例えば 億(収容失敗) →
→
→
などのように改善されます。比率で言うと絶対スコアは
倍 →
倍 →
倍と変化していて、相乗平均では倍率が大きいほど重要度が高いと判定するので、特に
倍の部分を大きく評価します。しかし実際は最後の
倍部分の影響が最も大きく、それ以外はほぼ影響ありません。
またこの例では、「① 前回の自分のスコアを使用」や「② 自分のスコアの最善値を使用する方法」を採用している場合、自身の解法が収容失敗しているケースでは収容失敗ペナルティが小さくなる影響を過大に評価してしまう可能性があります。実際にはトップ層にひとりでも収容成功している参加者がいると相対スコアに(ほぼ)影響しません。
解法の切り替わり
切り替わり付近では、上位陣がチャレンジ解法を使っているときに自分が安全解法を使っているとスコアは伸びないことが多いです。
ノーペナ達成
ノーペナの取りやすさやスコアシステム次第でどうするべきかが変わりますが、場合によってはノイズが大きくなるので必要に応じて調整してください。
(相対スコアとは少しずれますが) AHC025 では順位スコアが採用されていたので、ノーペナ(スコア 1 )が過大評価されていた可能性があります。
手元でのスコア、相加平均と相乗平均を両方使って参考にしてたけど、相乗平均は 100 ぐらい足せば良かったなと反省(そのままやるとスコア 1 がかなり強く影響してしまう)#AHC025
— きり (@kiri8128) October 22, 2023
まとめ
相対スコアが採用されている際の、パラメータ群の重要度把握、テストケースごとの行動最適化、解法の優劣比較について簡単なモデル化をして考察しました。
実際のコンテストでは上位陣の解法やスコアを予測しながら考える必要があり、本稿のモデルがそのまま使える訳ではないですが、戦略を立てるうえで参考になれば幸いです。
めも
記事がなかなかいい感じにまとまらない *26 のと、はてぶは一旦公開しないとプレビューが見づらいのと、段落リンクとかも取れないので一旦公開してしまえ!という気持ちで公開してみました。
記事ビムサっぽいことをしてる(とりあえず書いてみる → 途中で構成がいまいちになったら最初から書き直す or 一部消して書き直す → ・・・
— きり (@kiri8128) April 15, 2024
あとで追記・修正するかも。おかしな点や質問などあればこっそり教えてくださいー。
End
*1:重複もそこそこありますが
*2:このようなメタ戦略は、普段から考察している人にとっては当たり前の話と思われるかもしれません(初見ボドゲが得意な人は得意そう)
*3:この影響を考察するのが本稿の目的です
*4:厳密には確率的に変わる場合などもあり だけに依存する訳ではないがゆるふわで書いているので怪しいところは適宜察してください
*5:実際のコンテストでは全テストケースにおける相対スコアの「合計」が使われますが、テストケース数を考慮すると議論が複雑になるため「平均」で考えます
*6:なお、厳密にはこの条件を満たしている状態から特定のパラメータのみを伸ばすと条件が崩れてしまうんですが、微小変動のみを考慮するということでもろもろ許容することとしています。
*7:考察・実装などにかかる時間やリスクなどをまとめて「労力」と呼んでいます
*8:ここで、微分は のケースのみを動かしています。この意味で
の代わりに
を使ったり、左辺に何を固定したか明記したりする方法もありますが、ここではいろいろサボっています。
*9: が 0 付近のときは増減が逆になります。
*10:逆に言えば、これを意識しない場合にどれだけ無駄が生じうるか
*11:前述のとおり AHC 029 では増資回数制限があったので、ここまでひどいことにはなりません。おそらく Writer か運営があまりに極端にならないように配慮してくれたと思っています(感謝!)。本稿では、やや悪意があるように思える部分があるかもしれませんが、効率の重要性を強調するために敢えて極端な例も載せるようにしています。
*12:スコアがめちゃくちゃ取りにくいケースは逆に効率が下がるんですが、ここでは隠してます
*13:逆数のようなタイプは定式化が一意ではないのと、前提次第でグラフの形が大きく変わり、ミスリーディングになる可能性があるので描画は断念しました
*14:ポストの埋め込みを雑にやったので見づらい
*15:なんか当たり前のことを言ってますね
*16:テストケースが 1 つしかないような極端な場合は、ギャンブル戦略で確率が低くても 1 位を狙う方法があり得るので複雑になります
*17:余談ですが、私は AHC 030 本番中、前者の考え方をして 90% ぐらいを使っていたのですが、簡単なケースでかなり損していた計算になります。
*18:この罠は、相対スコアかどうかよりも逆数がかかるかどうかが大きいです。
*19:私自身が多数のケースを回すことをあまりしないのと、これやる人は強い人が多いのでどこまで書くかは迷ったんですが
*20:「絶対スコア上がったのに順位下がった~」のようなつぶやきを複数目撃して微妙な気持ちになっていました
*21:log を取るところの底が 2 ならここも底が 2 の指数関数で戻す
*22:きり体感
*23:これは小さいケースで計算量最適化をしている人ならモニターしている人も多かったと思います
*24:線形か指数的かその他かなど
*25:要出典
*26:特に「パラメータ群の重要度把握」と「解法の優劣比較」の両方に影響する「極端な例」は、 100 回ぐらい書いて消してをやった