AHC032 の考察記事です。
11,762 M 点で 18 位でした。
#AHC032 おつでした。
— きり (@kiri8128) April 7, 2024
11,762 で 18 位でした。
(解法)
1 マス 1 手を基準に上から貪欲に決めていきます。
・各行について、左の 4 マスに影響する置き方を全探索 → 右 5 マスを全探索
・一番下の 3 行は 6 マスずつ全探索 → 最後の 9 マスを全探索
動画は Seed0 (78,479M) pic.twitter.com/XvEz8nQkUI
ざっくり方針
- 1 マスで 1 手ずつ使う
- 上から順に、各行を 4 マス+ 5 マスに分けて全探索により最善手を選ぶ
- 下 3 列は 6 マスずつ全探索
- 最後の 9 マスは 9 手を全探索
お気持ち
- 試行回数に制限があるので、試行ごとの効率を最適化したい
- マス数と試行回数が一致しているので、基本的にはマスごとに試行 1 回を対応させたい
- きれいな法則がないので基本的には探索ゲーになる
- 本問では、選択肢があまり多くないことによる情報量的限界と、探索の計算時間的な限界の二つの側面がある
- 例えば焼きなまし法のように、探索時間を潤沢に使う方法は遅い言語では不利になりがち(Python だと辛い)
- 前者の限界以上の精度を出せる程度の探索を効率行えれば計算時間がネックになることはない
- 実際、本問では「行ごと」「4 列+5列」の全探索でこれを達成できる
前提
- 1 マスあたり 1 スタンプ使うことにする
- 2 マスで 2 スタンプなどは可とする
- 1 マス(だけ)のために 2 スタンプ押したり、 2 マスで 1 スタンプのように節約することは取り入れなかった
- 後者は実装できれば取り入れた方が良かった
詳細方針
左 4 マス全探索
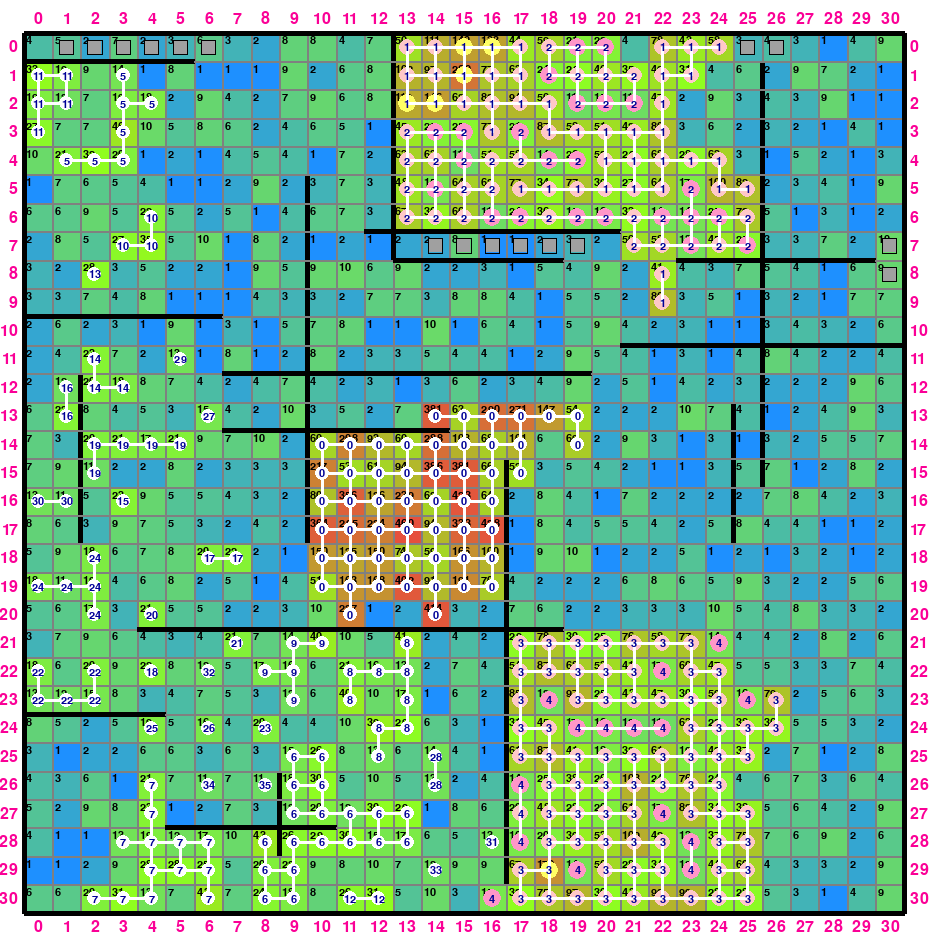
各行について、左から 4 マスに影響する置き方を考えます。具体的には、画像の灰色の部分を固定したときに、ピンクの部分の置き方を最適化したいです。
白の部分はあとで考えるので浸食して OK 。
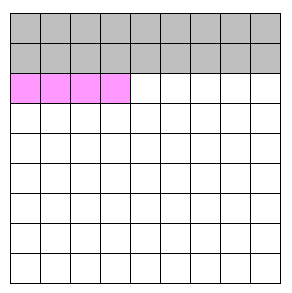
「1 マスあたり 1 スタンプ」ルールを考えると、許容される配置は、左上の位置のタプルで表すと の 13 パターン、どのスタンプを使うかを含めても 875,400 通りしかないので全探索できます。
なお、 や
などは「1 マス 1 スタンプ」を満たさないので省きました(前者は右端のマスが覆われず、後者は最初の 2 マスを 1 スタンプしかカバーしていない)。
右 5 マス全探索

こちらは置く位置のパターンは 8 通り、どのスタンプを使うかを含めても 5,140,800 通りありますが、最初の 3 マスが確定した時点で弱い場合は打ち切るなどの枝刈りでもう少し減らすことができます。
先ほどの 4 マスより 1 マス増えますが、右側にはみ出せないため置き方はあまり多くなりません。
下 3 行(6 マス全探索)

こちらは置く位置のパターンは 3 通り、どのスタンプを使うかを含めても 5,081,230 通りあります。最初の 3 マスが確定した時点で打ち切ると、若干減らすことができます。
下 3 行(最後の 9 マスを全探索)
こちらは置く位置は 1 とおり、どのスタンプを使うかは 6,906,900 通りあります。
これは枝刈りできないので全部頑張ります。
スコアの概算
問題がシンプルなので、実はある程度仮定を置くと「いくつかのマスについて全探索」を繰り返すような解法を前提にスコアの理論値が概算できます。
以下 とします。
1 マスに 1 回までスタンプを押す場合
1 マスの場合、そこを左上とするスタンプを置く方法は「無」のスタンプを押す方法も含めて 21 通りあります。これらが一様ランダムな場合の最小コストは、 です *1 。
仮に マスすべてこの誤差で置いたとすると、ケースあたりのスコアは約
になります。
一般の場合
より一般に マスで
通りを試すとき、最善パターンのペナルティを計算しましょう。
簡単のため で割って、マスごとのコストの分布が
の
確率変数 が
以上
以下の一様分布に従うとします。それらの合計
の密度関数は
次関数が複数つながった複雑な形になりますが、
(★)の範囲では
と表せます。
スタンプの押し方が 通りあるとして、簡単のためこれらの置き方によるペナルティが一様ランダムに存在すると近似します。
通り試したときの最小値は複雑な形になりますが、簡単のため該当付近が線形だと仮定すると 1 マス 1 スタンプの場合と同様、この逆関数の
分位点、すなわち
になります。
スタンプの押し方
1 個のマスに(そこを左上として)合計 個のスタンプを押す方法は
通りあります。
個のマスに合計
個のスタンプを押す方法は DP を用いて計算できます。
例えば本問全体では、 個のマスに
個のスタンプを押すことができますが、その方法は約
通りあります。
期待得点率
上記をもとに、 マスを最適化するためそのうち
マスに(そこを左上として)
個のスタンプを押すときの得点率
を計算することができます。
| 得点率 |
|||
最終解法期待値
例えば上に書いた私の解法では、理想的には、全体の得点率は
、すなわちケースあたり約
、合計
のスコアが得られることが期待できると分かります。
実際の私のスコアは とやや低くなっています。これは枝刈りによりすべて探索できていないことや、実際はすべての置き方が一様に分布していないことなどによるものと考えられます。
1マス - 3マス - 9マス 解法期待値
よりシンプルな解法として
- 左上の 6×6 部分は 1 マスだけ見て貪欲に決める
- 右 3 列は 3 マスずつ最適化する
- 下 3 列は 3 マスずつ最適化する
- 最後の 9 マスは 9 個のスタンプの置き方を最適化する
という方法があります。この場合の期待値は
、すなわちケースあたり約
、合計約
のスコアが得られることが期待できます。実は私の 第3提出 がこれだったのですが、ほぼ理論値通りの得点が得られていることが分かります *2 。
全体理論値
計算量を無視したこの問題の理論上の最適解スコアは、約 、
ケースだと約
になることが分かります *3 。
End